
記事公開日
最終更新日
並列処理の話(その1) ~変換処理の並行動作について(前編)~

(本記事の情報は、記事の公開日時点での情報であり、その正確性、完全性、最新性等内容を保証するものではありません。)
今回は、ETL:データ連携・加工における並列処理のお話をさせていただきます。
データ連携・加工では、連係して動作するシステム同士のスケジュールに沿って、限られた時間内に変換処理を終了しなければなりません。
p>例えば、DWH:データウェアハウスの場合、基幹系システムでとある日に更新されたデータを、日次処理の終了後から翌日の業務開始時間までの間に、DWHはもちろんその先のBIツールやレポーティングツールで参照・分析可能にしておかなければいけないはずです。この時間枠のことをバッチウィンドウと予備ます。限られたバッチウィンドウ内でデータ処理を終わらせるには、マルチコアCPUの利点を生かしたスケジューリングが必要になります。
通常、アプリケーションサーバー等におけるマルチコアCPUの利点は、同時多発的に発生するリクエストに対して複数のCPUコアが別々に動作できるということですが、ETLツールによるデータ連携の場合、複数のデータ処理を一つのジョブ(データ処理設定)にまとめて行うことができるので、ERPからBI・DWHへの日次データ連携といった処理だけではCPUコアが複数あっても、マルチコアCPUの一つ分だけしか使用しなくて済むことがあります(もちろん、そのサーバー上で他のサービスが起動していない場合)。
ETL:データ連携ツールにおけるマルチコアCPUの有効な利用法ということでは、一番簡単な方法は「複数のデータ変換・加工ジョブを同時に走らせる」事です。
まず、ファイルを読み込んで、加工し、別のファイルに保存するジョブを想定しましょう。
テスト用の入出力ファイルはおよお4,000万件-4GBで、このジョブ単独で実行すると、約136秒かかります。
テストに使用するマシンはCPUがCore i7で、4つの物理コアがハイパースレッドを積んでいますので、論理CPUは8つ。Windowsのタスクマネージャでは8つのCPUグラフを見ることが出来ます。
ハイパースレッドは物理コアの0.5ぐらいと言われますので、CPUパワーとしては6コア分になるわけですが、このジョブは6倍の速度では・・・動作しませんね。
プログラムは意識してマルチコアを使用しない限り、使われるコアはひとつだけです。
まぁ、1コアと比較すれば、裏で動作するOSや別のプロセスが並列動作しますので、少しは速くなるのですが。
さて、これと同じジョブが全部で10本あった場合、順番に実行すると136秒×10本=1,360秒かかることになります。
では、この10本をよーいドン!で同時に動かしたら、順番に10本動かすより速く終わるはずですよね?改行 CPU1個しか使用していない場合に比べて6倍のパワーがあるはずだからです。
実際にやってみましょう。
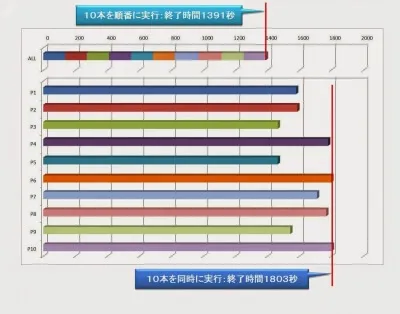
ところが、実際には順番に10本流した方が速いという結果になってしまいました。どうしてこんなことが起きるのでしょうか。
この問題を明確にするために、2本の場合、3本の場合と、順番にジョブを増やして行ってみましょう。 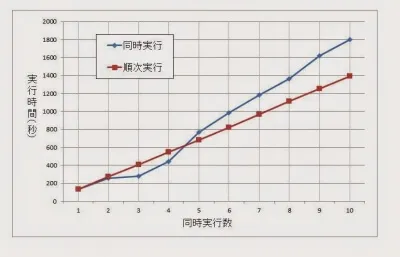
ジョブ2~4本を同時に動かした場合は、ジョブを直列で動かした場合より確かに速く終了しています。しかし、グラフで見ると5本目から直列よりも遅くなってきます。
しかもこのとき、CPU使用率は100%振り切っているわけではありません。
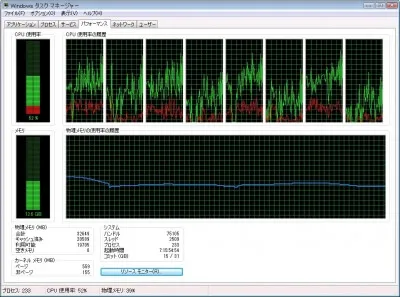
原因の解説は次回「並列処理の話(その1) ~変換処理の並行動作について(後編)~」に続きます。
関連コンテンツ
並列処理の話(その1) ~変換処理の並行動作について(後編)~
並列処理の話(その2) Windowsでコマンドを並列実行する(前編)
並列処理の話(その2) Windowsでコマンドを並列実行する(後編)
並列処理の話(その4) ハイパースレッディング・テクノロジー
基幹系システムと基幹システムの違いとは?情報系システムとは?
追記:Waha! Transformer 製品サイトの関連コンテンツ
BI:データ分析ツールの導入失敗をリカバリーするために必要な3つのポイント
データの抽出や加工、連携にお悩みではありませんか?
純国産ETLの決定版!25年以上の実績。異なる形式のデータをスムーズに連携・統合するノーコードETL:データ連携ツール「Waha! Transformer」がすぐにわかる「資料3点セット」はこちら。




